前言
Lab3主要是让我们实现一个单体的KV服务器,我是做完Lab4以后再回来对Lab3做的复盘,时间有点久远部分细节记不太清了,总的来说Lab3写起来还是挺舒服的,最后一个测试的网页可视化工具对我们DEBUG也很方便,这里稍微复习和记录一下写Lab3时踩过的大坑。 写Lab4之前强烈建议多测试几遍Lab3的代码,Lab4的分布式KV很多代码和思想都可以复用Lab3,在这里打好基础后后面的Lab4就会舒服许多,可以专心实现Lab4的分布式细节.
一定多看实验页面给的Hint
线性一致性
Lab3最核心的部分就是对线性一致性的理解。具体定义可以看这两篇文章
Testing Distributed Systems for Linearizability
nil.csail.mit.edu/6.5840/2023/notes/l-linearizability.txt
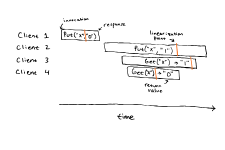
简而言之可以看这张图,有四个操作和四个客户端,他们操作耗时分别不一样,在分布式系统中,先开始的操作有可能再后开始操作之后才结束,而本次实验线性一致性的定义就是在这四个操作时间中,能找到 对应的时间点使得结果符合我们的预期 。比如看这幅图片,在这四个操作中无论什么时候开始结束,我们都能找到Put("x", "0"), Get("x") -> "0", Put("x", "1"), Get("x") -> "1",这就符合线性一致性。
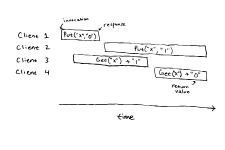
再看这幅图,无论我们怎么尝试都无法画出时间点使得结果合理。
 那么如何实现线性一致性呢?
就是利用我们的Raft,使得单体KV服务器群就操作(
那么如何实现线性一致性呢?
就是利用我们的Raft,使得单体KV服务器群就操作(Get ,PutAppend)达成顺序一致共识。
Get操作也要放到Raft中实现一致性!
Lab3的核心就是让我们设计实现符合线性一致性的KV系统。
重复检测(Replicate Detection)
看这篇实验给的文章就够了
nil.csail.mit.edu/6.5840/2023/notes/l-raft-QA.txt
每个Clerk客户端都应该有一个自己的独特ID和请求序列号,请求序列号用来标注这是当前clerk的第几次操作,用于在服务端那边过滤重复请求。
为什么要这么做呢?
clerk将请求发送到server时要通过start函数将操作共识到Raft中,这个过程是有可能会失败(可能发生Leader更替等情况)的,对于clerk而言不知道是否会失败,所以在共识后如果发生超时,clerk会进行重新尝试,这个时候就有可能导致操作被执行两次,所以我们要在server端为每个clerk维护一个LastSeq记录每个clerk最后一次成功应用的操作,clerk的相同的操作的序列号不会变,操作完成后才允许增加自己的操作ID。server端通过对比发来的seq操作序列号判断这个操作有没有执行过。
同样,针对Get请求,我们也需要维护一个DuplicateTable,用来返回查询结果。为什么Get这种不会造成值变化的操作也要维护呢?这是为了满足线性一致性。
只要执行成功,就应该返回对应时间点的值
例子:
C1 C2
put(x,10) first send of get(x), reply(10) dropped //回复10丢失 put(x,20) re-sends get(x), server gets 10 from table, not 20` // 重新发送get请求,此时还应该返回10而不是20
启动一个新协程执行来自applyCh共识结束的命令
func (kv *KVServer) ExectuteOp() {
for {
msg := <-kv.applyCh
//如果是旧的日志,直接跳过
if kv.LastApplyIndex > msg.CommandIndex && msg.CommandValid {
continue
}
//只能安装比上次快照大的index
if kv.LastSnapshotIndex > msg.SnapshotIndex && msg.SnapshotValid {
continue
}
if msg.CommandValid {
op := msg.Command.(Op)
kv.mu.Lock()
//泛型判断操作类型
if op.Type == GetType {
args := op.Cmd.(GetArgs)
//如果操作已经被执行过
if args.Seq <= kv.LastSeq[args.ClientID] {
kv.mu.Unlock()
continue
}
if _, ok := kv.DupGetTab[args.ClientID]; !ok {
kv.DupGetTab[args.ClientID] = make(map[int64]GetReply)
}
kv.DupGetTab[args.ClientID][args.Seq] = GetReply{Value: kv.Data[args.Key], Err: OK}
kv.LastSeq[args.ClientID] = args.Seq
} else if op.Type == PutType {
args := op.Cmd.(PutAppendArgs)
//如果操作已经被执行过
if args.Seq <= kv.LastSeq[args.ClientID] {
kv.mu.Unlock()
continue
}
kv.Data[args.Key] = args.Value
kv.LastSeq[args.ClientID] = args.Seq
} else if op.Type == AppendType {
args := op.Cmd.(PutAppendArgs)
if args.Seq <= kv.LastSeq[args.ClientID] {
kv.mu.Unlock()
continue
}
if _, ok := kv.DupGetTab[args.ClientID]; !ok {
kv.DupGetTab[args.ClientID] = make(map[int64]GetReply)
}
kv.Data[args.Key] += args.Value
kv.LastSeq[args.ClientID] = args.Seq
}
kv.LastApplyIndex = msg.CommandIndex
kv.mu.Unlock()
} else if msg.SnapshotValid {
//Snapshot
kv.mu.Lock()
kv.readPersist(msg.Snapshot)
kv.mu.Unlock()
}
}
}
Get PutAppend 客户端代码
func (ck *Clerk) Get(key string) string {
ck.mu.Lock()
ok := false
var reply *GetReply
i := ck.LastLeader
args := GetArgs{
Key: key,
ClientID: ck.UUID,
Seq: ck.Seq,
}
for !ok || reply.Err != OK {
reply = &GetReply{}
reply.Err = ""
flag := make(chan bool)
go func() {
ok = ck.servers[i].Call("KVServer.Get", &args, &reply)
flag <- true
}()
select {
case <-flag:
case <-time.After(500 * time.Millisecond):
}
i = nrand() % int64(len(ck.servers))
}
ck.Seq++
ck.LastLeader = reply.Leader
ck.mu.Unlock()
return reply.Value
}
func (ck *Clerk) PutAppend(key string, value string, op string) {
ck.mu.Lock()
ok := false
var reply *PutAppendReply
i := ck.LastLeader
args := PutAppendArgs{
Key: key,
Value: value,
Op: op,
ClientID: ck.UUID,
Seq: ck.Seq,
}
for !ok || reply.Err != OK {
reply = &PutAppendReply{}
reply.Err = ""
flag := make(chan bool)
go func() {
ok = ck.servers[i].Call("KVServer.PutAppend", &args, &reply)
flag <- true
}()
select {
case <-flag:
case <-time.After(500 * time.Millisecond):
}
i = nrand() % int64(len(ck.servers))
}
ck.Seq++
ck.LastLeader = reply.Leader
ck.mu.Unlock()
}
服务端操作
func (kv *KVServer) Get(args *GetArgs, reply *GetReply) {
reply.Err = OK
cmd := Op{Type: GetType, Cmd: *args}
kv.mu.RLock()
if rpl, ok := kv.DupGetTab[args.ClientID][args.Seq]; ok {
reply.Err = OK
reply.Value = rpl.Value
kv.mu.RUnlock()
return
}
kv.mu.RUnlock()
_, _, isLeader := kv.rf.Start(cmd)
if !isLeader {
reply.Err = ErrWrongLeader
return
}
reply.Leader = int64(kv.me)
for {
select {
case <-time.After(200 * time.Millisecond):
reply.Err = ErrAgreement
return
default:
kv.mu.RLock()
if rpl, ok := kv.DupGetTab[args.ClientID][args.Seq]; ok {
reply.Err = OK
reply.Value = rpl.Value
kv.mu.RUnlock()
return
}
kv.mu.RUnlock()
time.Sleep(10 * time.Millisecond)
}
}
}
func (kv *KVServer) PutAppend(args *PutAppendArgs, reply *PutAppendReply) {
reply.Err = OK
cmd := Op{}
cmd.Cmd = *args
//说明是很久以前的请求,让client重新发送
kv.mu.RLock()
if kv.LastSeq[args.ClientID] >= args.Seq {
kv.mu.RUnlock()
reply.Err = OK
return
}
kv.mu.RUnlock()
if args.Op == "Put" {
cmd.Type = PutType
} else {
cmd.Type = AppendType
}
_, _, IsLeader := kv.rf.Start(cmd)
if !IsLeader {
reply.Err = ErrWrongLeader
return
}
reply.Leader = int64(kv.me)
for {
select {
case <-time.After(200 * time.Millisecond):
reply.Err = ErrAgreement
return
default:
kv.mu.RLock()
if kv.LastSeq[args.ClientID] >= args.Seq {
reply.Err = OK
kv.mu.RUnlock()
return
}
kv.mu.RUnlock()
time.Sleep(10 * time.Millisecond)
}
}
}
QPS过低
在lab2中,我设置的心跳间隔是50ms,这导致了就算来了新操作Raft也会把这些操作攒到一起等50ms再发出去,这样导致了qps过低,这里应该改进为收到后就立马发出。
在我的实现中,lab2又不能发出去的太快,否则虽然能过Lab3的qps测试了,但过不了lab2的测试,所以我设置了10ms发送,Lab2和lab3都能稳定一百次通过。
func (rf *Raft) Start(command interface{}) (int, int, bool) {
index := -1
term := -1
isLeader := true
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.currentStatus != 3 {
return index, term, false
}
term = rf.currentTerm
lg := LogEntry{
Term: term,
Cmd: command,
}
rf.log = append(rf.log, lg)
index = len(rf.log) - 1 + rf.lastIncludedIndex
rf.persist(rf.Persister.ReadSnapshot())
if rf.hbTicker != nil {
rf.hbTicker.Reset(10 * time.Millisecond)
}
//给所有follower发送AppendEntries
// Your code here (2B).
return index, term, isLeader
Snapshot
前面的实现完的话,快照部分就简单了,就是一个新起一个Snapshot协程定时判断是否大于约定大小,大于的话就调用Raft裁剪就行了。同时在applyCh那边监听Leader发过来的安装快照就行了,需要注意的是不能什么东西都往快照持久化里面扔,测试脚本有判断快照大小的测试,DuplicateTable就不用持久化。
func (kv *KVServer) SnapshotRaft() {
if kv.maxraftstate == -1 {
return
}
for {
time.Sleep(200 * time.Millisecond)
RaftSize := kv.rf.Persister.RaftStateSize()
if RaftSize > kv.maxraftstate-500 {
kv.mu.Lock()
if kv.LastApplyIndex <= kv.LastSnapshotIndex {
kv.mu.Unlock()
continue
}
kv.rf.Snapshot(kv.LastApplyIndex, kv.persist())
kv.LastSnapshotIndex = kv.LastApplyIndex
kv.mu.Unlock()
}
}
}
func (kv *KVServer) persist() []byte {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(kv.Data)
e.Encode(kv.LastSeq)
e.Encode(kv.LastApplyIndex)
e.Encode(kv.LastSnapshotIndex)
return w.Bytes()
}
func (kv *KVServer) readPersist(data []byte) {
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
d.Decode(&kv.Data)
d.Decode(&kv.LastSeq)
d.Decode(&kv.LastApplyIndex)
d.Decode(&kv.LastSnapshotIndex)
}
还写了个小GC,不过好像在Lab3里面没啥用,到Lab4的Chanllenge里面居然发挥作用了。
// 简单垃圾回收
func (kv *KVServer) GC() {
for {
//STW !!!
time.Sleep(200 * time.Millisecond)
kv.mu.Lock()
for client, seq := range kv.DupGetTab {
for s, _ := range seq {
if kv.LastSeq[client]-200 > s {
delete(kv.DupGetTab[client], s)
}
}
}
kv.mu.Unlock()
}
}
总结
Lab3是我写的最舒服的一个Lab,没有刚遇到Lab2 Unreliable网络环境下的迷茫,又不用关心Lab4中配置变更和分片转移的问题,感觉自己的进步很大,写微服务时也开始考虑以前不会去测试和思考的问题,我觉得程序员很重要的一个能力就是跳出舒适圈,不能每天只写一些简单重复的东西,而是应该去多挑战一下困难,这样才可以带来技术和心态的成长。
最后附上通关截图